A plataforma Planalyzing
Simplificando a Avaliação Empírica de Planejadores Automatizados
A plataforma é projetada para automatizar a avaliação de planejadores, permitindo que os usuários realizem o agendamento, a execução e a análise de experimentos de forma reprodutível em um conjunto de domínios e problemas conforme a Tabela 1, que lista todos os domínios e a quantidade de problemas em cada um, avaliados pela plataforma. Essa abordagem otimiza o processo de avaliação, eliminando tarefas repetitivas e reduzindo os esforços manuais. Além disso, o usuário também pode selecionar os domínios e problemas de interesse, bem como adicionar novos domínios para sua análise.
Uma das principais dificuldades na avaliação de um conjunto de planejadores em um lote de problemas, considerando um conjunto de métricas de interesse, está na seleção e no relacionamento eficaz dos seguintes elementos:
- seleção do(s) planejador(es)
- seleção do(s) domínio(s) e problema(s);
- coleta das mesmas métricas, em diferentes formatos, fornecidas como saída dos planejadores;
- combinação, em um único experimento, de planejadores, domínio(s) e problema(s);
- gerenciamento do histórico de avaliações por planejador, domínios e problema; e
- comparações em gráficos e tabelas, dentre os resultados internos dos experimentos ou comparações entre experimentos diferentes.
A plataforma busca minimizar a complexidade inerente à avaliação de planejadores, integrando componentes que desempenham tarefas críticas de maneira automatizada. Entre essas funcionalidades, destacam-se:
- controle do tempo máximo de execução por planejador e problema;
- controle do tamanho máximo de memória disponível para executar cada problema;
- uso de ambientes virtualizados Docker para a execução isolada de experimentos em ambientes controlados;
- coleta e processamento automatizado de métricas de desempenho; e
- geração de relatórios analíticos detalhados.
Note que os experimentos são executados em contêineres criados por Dockers em diferentes ambientes, mantendo a compatibilidade, reduzindo os riscos de conflitos entre softwares e aumentando a segurança em ambientes compartilhados. A plataforma tem como objetivo facilitar a execução de tarefas em clusters de computação, permitindo que usuários não precisem de permissões especiais para executar contêineres. Essa integração aumenta a eficiência operacional e promove a transparência em todas as etapas do processo experimental, permitindo que os resultados sejam facilmente compreendidos e replicados, contribuindo para o avanço da pesquisa e para o desenvolvimento da área.
A plataforma é uma extensão do trabalho apresentado no repositório MUISE (2024a), que avalia planejadores totalmente observáveis não-determinísticos (FOND). O código implementa testes em diversos domínios, problemas e planejadores, executados via linha de comando em sistemas Linux. Por meio de um Jupyter Notebook, os resultados são resumidos em tabelas e gráficos.
Tabela 1. Domínios e Problemas
| Domínios | Problemas |
|---|---|
| acrobatics | 8 |
| beam-walk | 11 |
| blocksworld | 37 |
| blocksworld-2 | 16 |
| blocksworld-new | 51 |
| chain-of-rooms | 10 |
| doors | 15 |
| earth-observation | 40 |
| elevators | 16 |
| ex-blocksworld | 15 |
| first-responders | 101 |
| forest | 90 |
| forest-new | 100 |
| islands | 60 |
| miner | 51 |
| rectangle-tireworld | 30 |
| rectangle-tireworld-noghost | 30 |
| st_blocksworld | 30 |
| st_first_responders | 75 |
| st_tires | 14 |
| tidyup-mdp | 10 | tireworld | 16 |
| tireworld-spiky | 11 |
| tireworld-truck | 74 |
| triangle-tireworld | 42 |
| zenotravel | 16 |
| Total (26) | 969 |
Os gráficos comparam os planejadores com o PR2 (MUISE, 2024b), permitindo avaliar o desempenho dos demais em relação ao tempo de execução e ao tamanho das soluções geradas pelo PR2.
O código de avaliação do PR2 ainda está em desenvolvimento, mas permitiu explorar e compreender o processo de testes, incluindo a estrutura de diretórios, bem como os arquivos relacionados a domínios, problemas e planejadores. Com base nesse estudo preliminar, foi possível adicionar novos planejadores e realizar testes fora do escopo original do projeto. A partir desse entendimento, surgiu a proposta da plataforma Planalyzing, com o objetivo de automatizar esse processo, atualmente manual e que exige conhecimento técnico em linguagens de programação, arquitetura de sistemas, ambientes Linux e virtualização de contêineres.
Bibliografia
PR2 is the next iteration in the evolution of SoA non-deterministic planning
Author(s): Christian Muise
Journal: No Journal
Year: 2024
Para modelar o sistema, usamos a linguagem C4. O Modelo C4 é uma abordagem estruturada para a visualização de arquiteturas de sistemas de software. Ele se concentra em oferecer uma visão estática do sistema, destacando tanto a estrutura quanto a interação entre seus diferentes componentes. Essa abordagem é organizada em quatro níveis hierárquicos de abstração, cada um capturado por um tipo de diagrama específico:
- Diagrama de Contexto: fornece uma visão geral do sistema, destacando como ele se relaciona com os usuários e outros sistemas externos.
- Diagrama de Contêiner: detalha os principais contêineres de software do sistema (por exemplo, aplicações, serviços e bancos de dados) e suas interações.
- Diagrama de Componente: foca na estrutura interna de cada contêiner, descrevendo os componentes e suas interdependências.
- Diagrama de Código: apresenta os detalhes mais granulares da implementação, como classes, métodos e funções, quando necessário.
Ao decompor a arquitetura em diferentes níveis de abstração, o modelo C4 permite uma comunicação clara entre as partes interessadas, desde desenvolvedores até gerentes de projeto e outros membros não-técnicos da equipe.
Para avaliar a plataforma, será submetido à análise o planejador PACTL-Sym (SANTOS et al., 2024), um planejador simbólico, que implementa a semântica da lógica alpha-CTL para planejamento totalmente observável não-determinístico (FOND). Esse planejador, usado como referência para avaliar a plataforma, foi desenvolvido por alunos de pós-graduação do curso de Ciência da Computação da Universidade de São Paulo.
A seguir, apresentaremos a modelagem da plataforma baseada na linguagem C4.
Contexto do Sistema
O diagrama de contexto representa a visão de mais alto nível de um sistema de software, oferecendo uma perspectiva de como o sistema se integra ao ecossistema em que está inserido. Nesse diagrama, o sistema é retratado como uma única entidade (ou caixa), cercada por seus usuários, também chamados de atores, e pelos outros sistemas com os quais interage.
Essa visualização serve para destacar os principais relacionamentos e fluxos de informação entre o sistema e seu ambiente externo. Como ponto de partida, o diagrama de contexto estabelece uma visão geral fundamental, preparando o terreno para os diagramas subsequentes, que exploram os detalhes internos do sistema em níveis mais granulares. A Figura 1, mostra o contexto da plataforma.
O diagrama apresentado na Figura 1, ilustra como o sistema interage com seus principais atores (stakeholders) e seus componentes internos. A plataforma é representada como um único sistema composto por diferentes contêineres que desempenham papéis específicos.
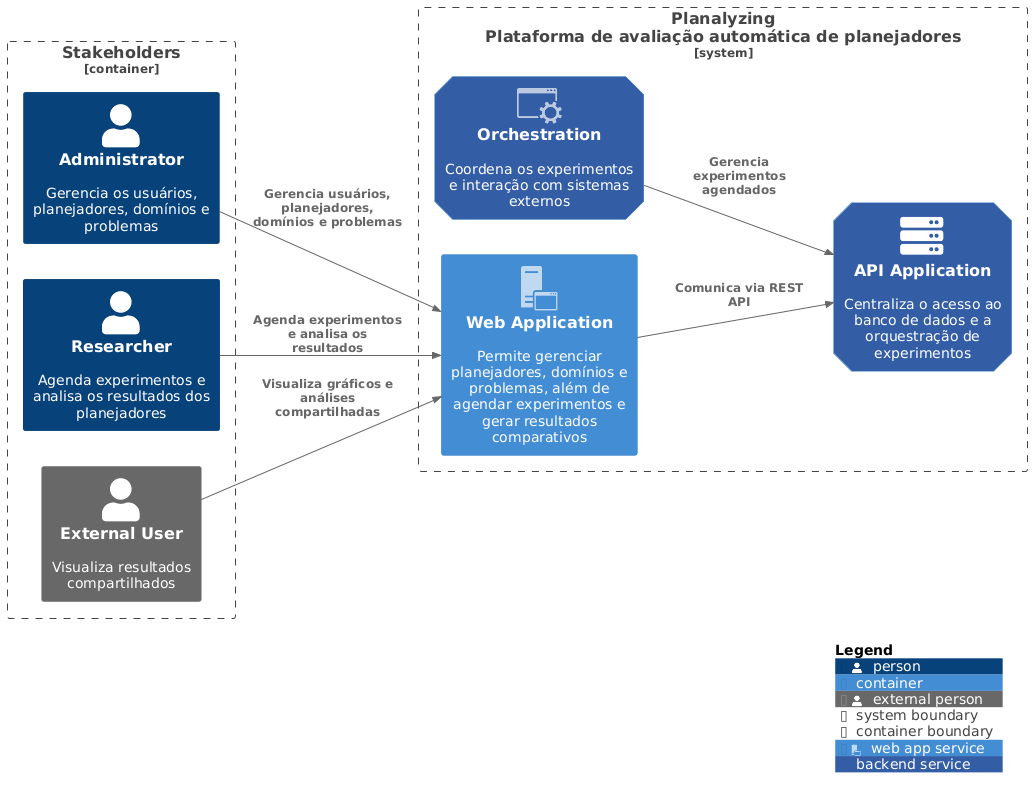
- Stakeholders (Usuários)
- Administrator: Responsável por gerenciar usuários, planejadores, domínios e problemas no sistema.
- Researcher: Agenda experimentos, analisa resultados dos planejadores e visualiza gráficos e análises compartilhadas.
- External User: Visualiza os resultados compartilhados gerados pelos pesquisadores.
- Plataforma Planalyzing (Componentes do Sistema)
- Orchestration: Coordena os experimentos e gerencia interações com sistemas externos, garantindo que os experimentos agendados sejam processados de forma eficiente.
- Web Application: Serve como interface principal para gerenciar planejadores, domínios e problemas. Permite aos usuários agendar experimentos e visualizar resultados comparativos, funcionando como um ponto de interação para os administradores e pesquisadores.
- API Application: Centraliza o acesso ao banco de dados e gerencia a orquestração dos experimentos, comunicando-se via REST API com outros componentes.
- Administrator: Interage diretamente com a Web Application para gerenciar usuários, planejadores, domínios e problemas, populando os dados básicos que serão utilizados no agendamento e execução dos experimentos.
- Researcher: Também utiliza a Web Application para agendar experimentos, analisar resultados e visualizar gráficos.
- Orchestration: Responsável por coordenar a execução dos experimentos agendados por meio da aplicação web. Esse componente se comunica diretamente com a API Application para acessar o banco de dados e obter as informações necessárias para a execução dos experimentos. Além disso, estabelece conexões com outros sistemas externos, garantindo a integração e o fluxo de informações para o funcionamento da plataforma.
- External User: Acessa resultados compartilhados, que são disponibilizados através da interface Web.
Diagrama de Contêiner
O Diagrama de contêiner oferece uma visão mais detalhada da arquitetura do sistema, mantendo um nível de abstração suficiente para ser acessível e facilmente compreendido por partes interessadas não técnicas. Ele destaca os principais contêineres que compõem o sistema e suas interações, possibilitando uma visão clara e simplificada da estrutura geral. A Figura 2, descreve a arquitetura do sistema que é composta por diversos contêineres, cada um desempenhando funções específicas e interdependentes, formando um ecossistema integrado para a avaliação de planejadores automatizados.
A interação entre os componentes da plataforma é mediada principalmente pela Orchestration, que centraliza a coordenação dos experimentos, conectando usuários, sistemas internos e externos. A Web Application funciona como a interface principal para os usuários, oferecendo ferramentas para gerenciar planejadores, domínios e problemas, além de agendar experimentos e visualizar resultados. Os stakeholders, como administradores e pesquisadores, utilizam esta aplicação para interagir com a plataforma, enquanto os usuários externos têm acesso restrito para visualizar resultados compartilhados.
A Web Application comunica-se diretamente com a API Application, que é responsável por centralizar o acesso aos dados armazenados no banco de dados e gerenciar as operações associadas, como a consulta de experimentos e o gerenciamento de tokens de autenticação. Essa estrutura permite que o sistema seja flexível e responsivo às necessidades dos usuários, mantendo uma clara separação entre interface, lógica de aplicação e dados.
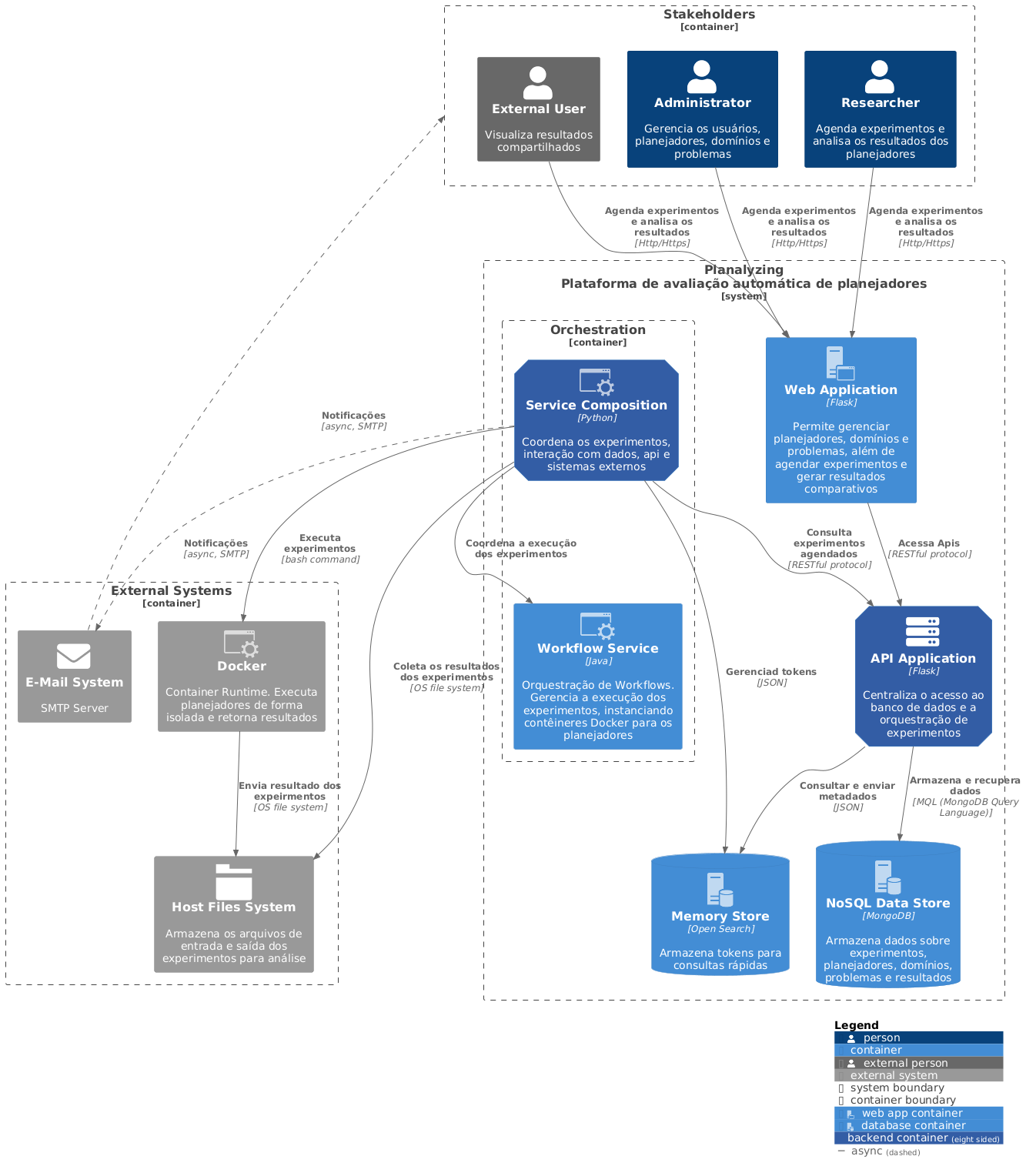
O Orquestrador é um componente central no sistema, cuja finalidade é gerenciar a execução de experimentos e coordenar as interações com outros serviços e sistemas externos. Esse contêiner está subdividido em dois módulos principais: o Service Composition, que controla as interações de alto nível, e o Workflow Service, que orquestra a execução de workflows e instanciamento de contêineres Docker para execução de planejadores.
O Workflow Service é responsável por garantir que os experimentos sejam realizados de forma isolada e controlada, utilizando contêineres para executar os planejadores e coletar os resultados, que são posteriormente armazenados em sistemas de arquivos. Paralelamente, o Service Composition gerencia a comunicação assíncrona, enviando notificações aos usuários sobre o progresso dos experimentos via sistemas de e-mail externo. Essa segmentação permite que o sistema mantenha um fluxo de execução e comunicação, garantindo a integridade dos experimentos e a entrega de notificações aos stakeholders.
Os dados gerados e consumidos pelo sistema são armazenados e gerenciados por dois contêineres dedicados: o NoSQL Data Store e o Memory Store. O NoSQL Data Store, baseado em MongoDB, armazena informações sobre experimentos, planejadores, domínios, problemas e resultados, oferecendo uma base de dados para consultas e análise. Já o Memory Store é utilizado para armazenar dados, como pares chave/valor, otimizando a performance em operações de consulta rápidas.
Esses dois contêineres interagem diretamente com a API Application, que atua como um intermediário para gerenciar as requisições dos usuários e da Orchestration. Por fim, o sistema também depende de serviços externos, como o E-Mail System para envio de notificações e o Host Files System para armazenar entradas e saídas dos experimentos.
Diagrama de Componentes do Orquestrador
O Diagrama de componentes é o terceiro nível de abstração no modelo C4. Ele detalha cada contêiner, dividindo seus componentes principais e revelando suas interações e relacionamentos. Esses componentes podem ser classes, interfaces ou módulos que oferecem funcionalidades específicas. Esse nível de detalhamento é especialmente útil para os desenvolvedores, pois fornece uma visão detalhada da estrutura interna do sistema e facilita a compreensão da arquitetura.
Nessa modelagem, descreveremos em detalhes o processo de automação, mostrado na Figura 3. Cada etapa é detalhada através do diagrama de componentes do orquestrador Figura 4, que é dividido em dois módulos principais, o Workflow Service e o Service Composition, que coordenam a execução dos experimentos em diferentes níveis de granularidade.
No Workflow Service, elementos como o DAG Scheduler gerenciam o fluxo dos experimentos agendados, enquanto processos mais específicos, como o Run Experiments DAG e o Extract Results DAG, são responsáveis por executar experimentos e extrair métricas. Esses componentes trabalham em conjunto para garantir que as tarefas sejam realizadas de maneira orquestrada e com integração entre os serviços internos e externos. Esse comportamento é refletido no fluxograma, que descreve as etapas sequenciais do processo, desde a consulta de experimentos agendados até a coleta e notificação dos resultados.
No Service Composition, componentes como o ScheduleManager, ExperimentManager e ResultProcessor desempenham papéis essenciais na automação e gerenciamento das execuções. O ScheduleManager agenda experimentos na esteira de execução, alinhado à lógica do fluxograma, onde os experimentos são validados antes de sua execução. O ExperimentManager, por sua vez, instancia contêineres Docker para executar planejadores de forma isolada, garantindo a reprodutibilidade dos experimentos e a integridade dos dados, enquanto o ResultProcessor analisa os arquivos de saída, extrai métricas e as armazena no banco de dados para posterior consulta e análise.
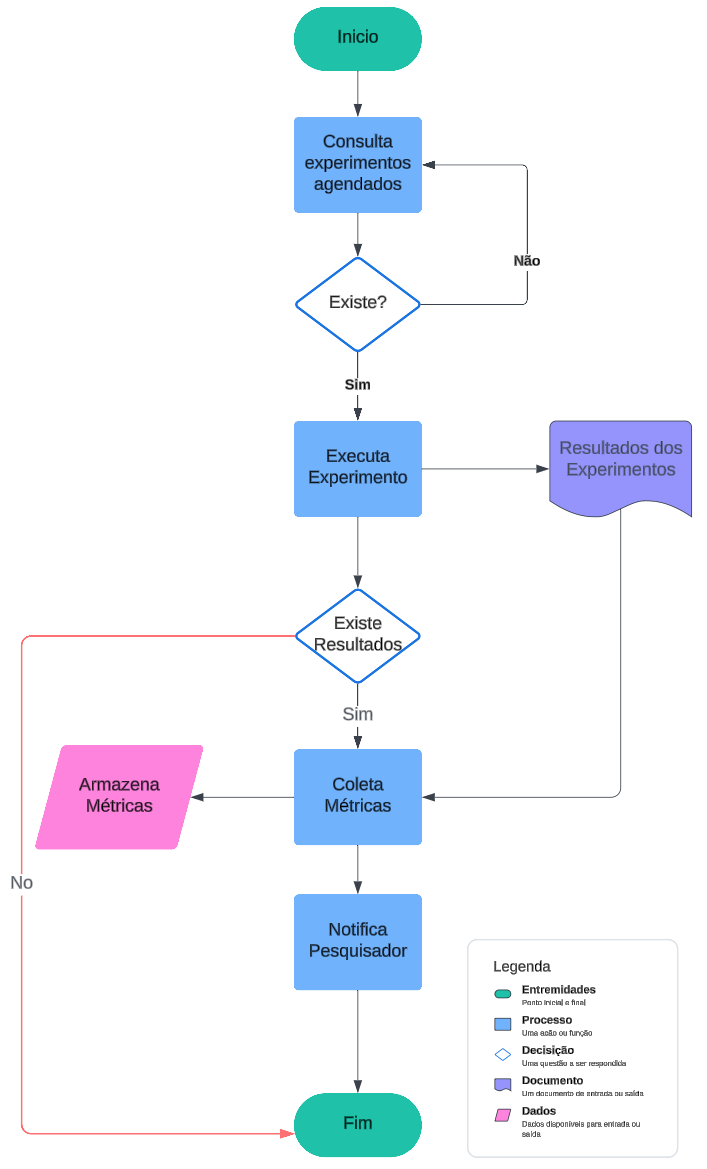
Paralelamente, componentes como o CommandGenerator e o NotificationManager geram comandos para execução e notificações para os usuários, garantindo que o sistema seja responsivo às interações humanas e automatize os feedbacks necessários, como mostrado no fluxograma na etapa de notificação dos resultados.
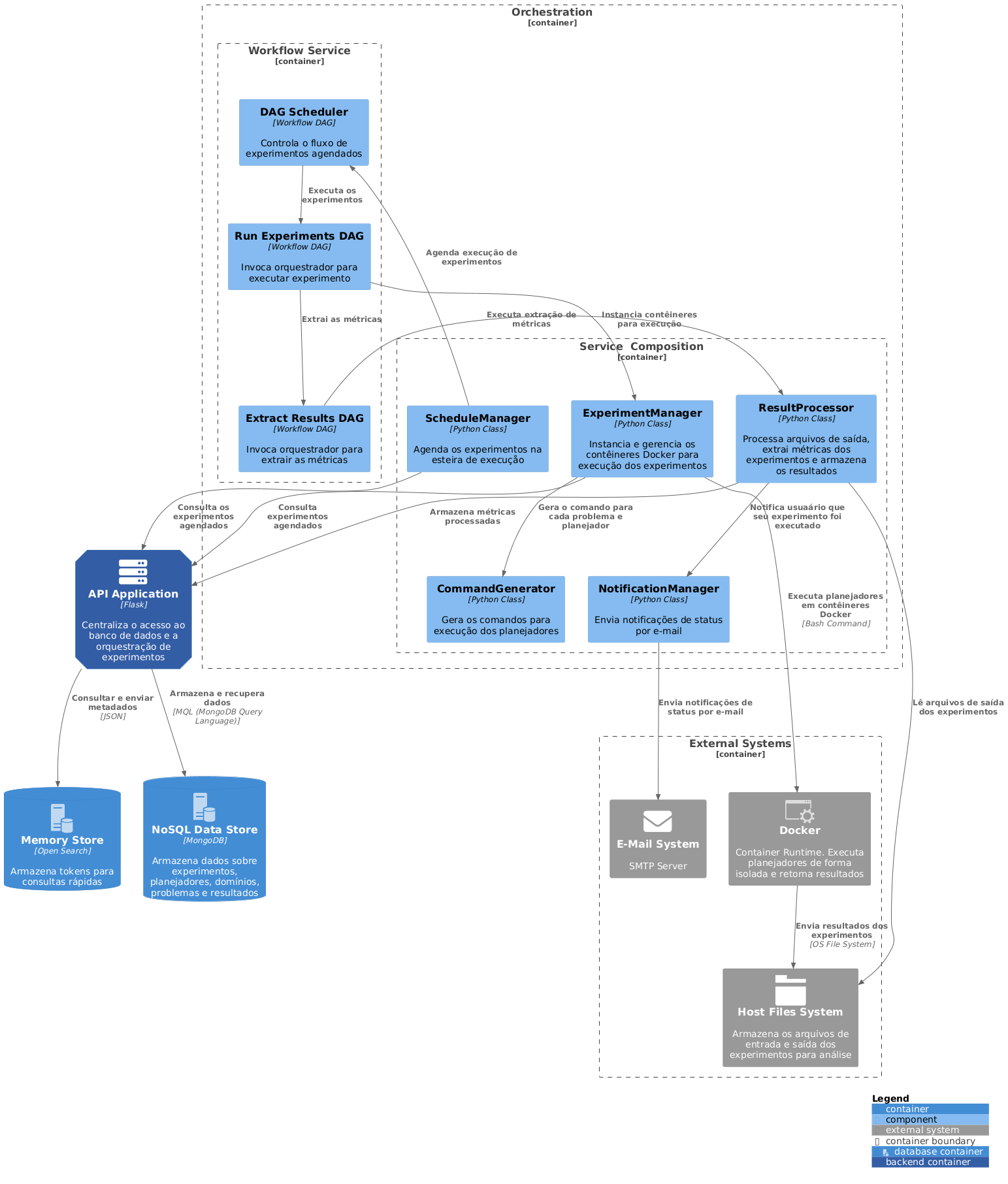
A consulta de experimentos agendados pelo DAG Scheduler corresponde ao início do processo no fluxograma, enquanto a execução de experimentos e extração de métricas são etapas representadas pelos componentes Run Experiments DAG e Extract Results DAG. O ciclo se fecha com a coleta de métricas, realizada pelo ResultProcessor, e a notificação ao pesquisador, representada no fluxograma como a etapa final antes do encerramento do processo.
A integração entre os módulos do orquestrador e os sistemas externos, como o Docker e o E-Mail System, garante que cada etapa seja realizada com total automação, garantindo a capacidade de gerenciar experimentos complexos de forma escalável e confiável.
Diagrama de Código do Orquestrador
A Figura 5, representa o nível final de abstração, mostra os detalhes de componentes individuais, classes importantes, interfaces e seus relacionamentos, normalmente usado por desenvolvedores para projetar e implementar o sistema.
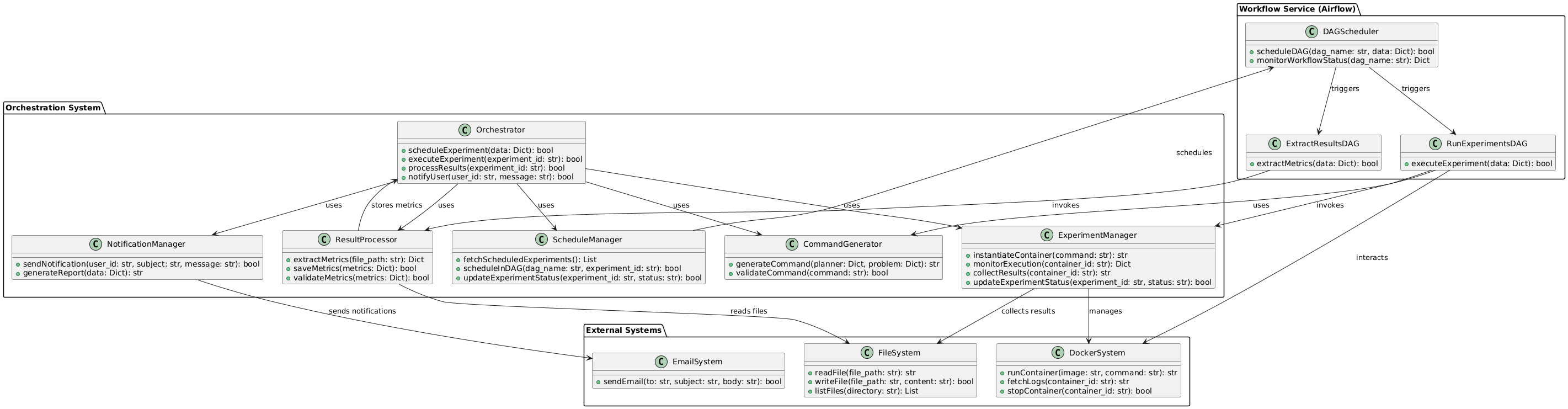
O orchestrator usa o ScheduleManager para agendar experimentos e o CommandGenerator para criar comandos de execução. Durante a execução, o ExperimentManager gerencia os contêineres Docker e coleta os resultados. Após a execução, o ResultProcessor lê os resultados do sistema de arquivos, extrai métricas e salva no banco de dados. Por fim, o NotificationManager informa os usuários sobre o status e a conclusão do experimento.
Bibliografia
Symbolic FOND Planning for Temporally Extended Goals
Author(s): Viviane Bonadia dos Santos and Leliane Nunes de Barros and Silvio do Lago Pereira and Maria Viviane de Menezes
Journal: No Journal
Year: 2024
Modelo de Dados
O modelo de dados da Figura 6 é estruturado em coleções no MongoDB, cada uma representando um conceito fundamental no sistema. A coleção Domains armazena os domínios de planejamento, definidos por um identificador único (_id), um nome descritivo, uma descrição detalhada, e as datas de criação e atualização. Cada domínio também inclui o campo created_by, que identifica o usuário que registrou o domínio, e o campo is_approved, que indica se o domínio foi aprovado por um administrador. Apenas domínios aprovados estão disponíveis para serem listados ou utilizados. Esses domínios servem para agrupar e organizar os problemas de planejamento, que são armazenados na coleção Problems. Cada problema está associado a um domínio através do campo domain_id e inclui informações como o nome do problema, o caminho do arquivo que contém sua definição (file_path), além de metadados sobre criação e atualização. Assim como nos domínios, problemas possuem os campos created_by e is_approved, garantindo controle sobre quem os registrou e se estão disponíveis para uso.
A coleção Planners armazena informações sobre os planejadores disponíveis no sistema. Cada planejador possui um identificador único, um nome, uma descrição, e uma lista de versões. Cada versão inclui um número de versão (version_number), o comando necessário para sua execução (execution_command), o padrão dos arquivos de saída gerados (output_pattern) e as métricas que podem ser extraídas desses arquivos. Essas métricas são armazenadas como pares de nome e expressão regular, permitindo a análise dos resultados após a execução. Cada planejador também contém os campos created_by e is_approved, garantindo que apenas planejadores aprovados possam ser utilizados em experimentos. Esses planejadores são fundamentais para configurar experimentos, que são registrados na coleção Experiments.
A coleção Experiments representa os experimentos agendados e executados no sistema. Cada experimento é descrito por um identificador único, uma descrição textual, uma lista de planejadores e suas versões, e os problemas associados. Os problemas são organizados por nome do domínio e arquivos de problemas específicos ou, quando aplicável, a indicação de que todos os problemas do domínio devem ser utilizados. Adicionalmente, o experimento contém os campos is_shared_internal e is_shared_external, que controlam o compartilhamento de resultados entre usuários do sistema e usuários externos, respectivamente. O experimento também armazena informações sobre a data de criação, o agendamento (scheduled_at) e o status atual (como “agendado” ou “concluído”). Após a execução de um experimento, os resultados são armazenados na coleção Results.
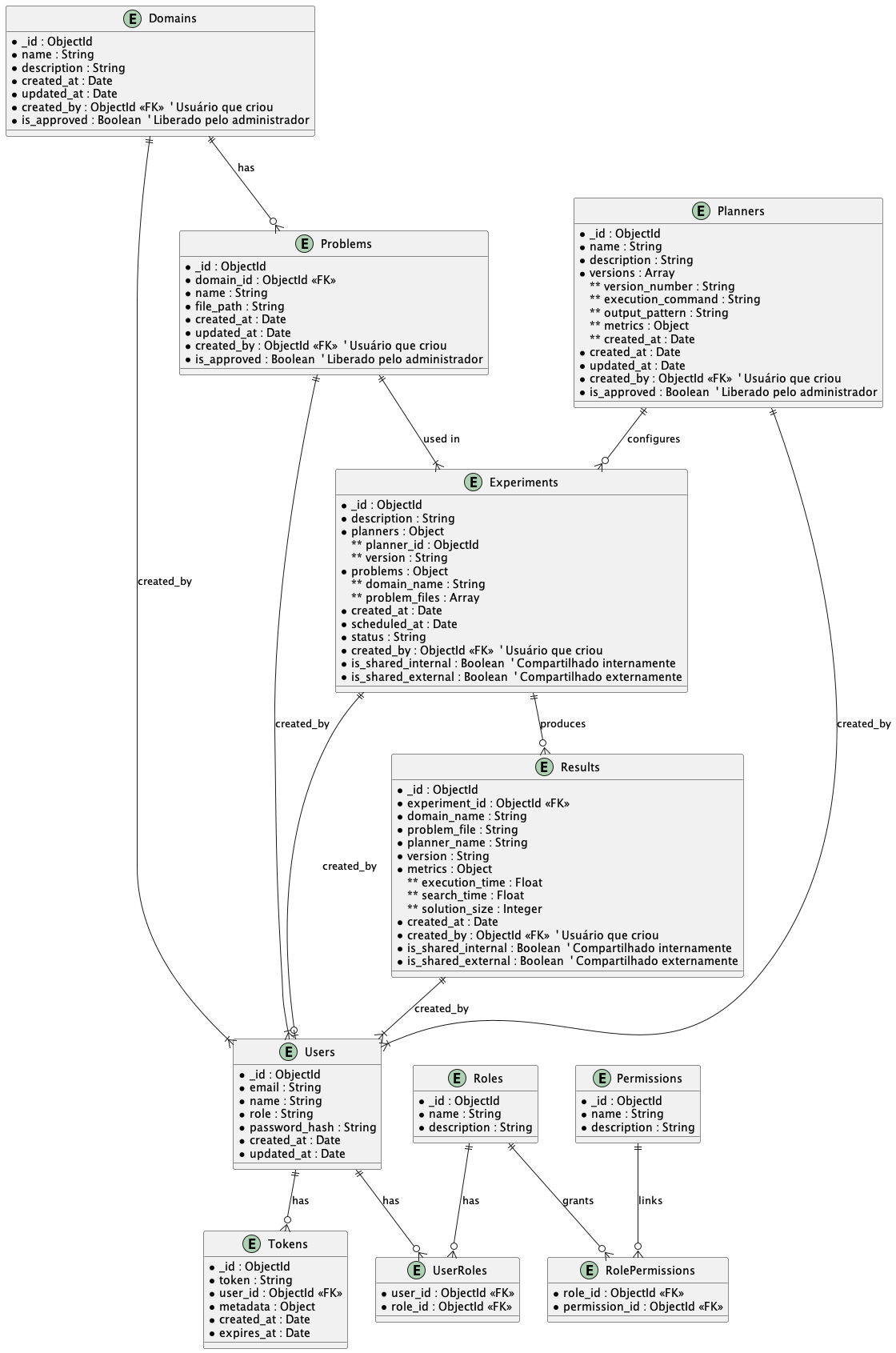
A coleção Results armazena os dados extraídos dos experimentos. Cada resultado está associado a um experimento específico (experiment_id) e inclui informações como o domínio, o arquivo de problema, o nome do planejador, a versão utilizada e as métricas extraídas. Essas métricas incluem tempo de execução total (execution_time), tempo de busca (search_time) e o tamanho da solução gerada (solution_size) como padrão, mas podem ser estendidas. Assim como nos experimentos, os resultados possuem os campos is_shared_internal e is_shared_external, permitindo controle sobre a visibilidade dos dados. Esses resultados são a base para as análises posteriores e são acessados por usuários, que são gerenciados na coleção Users.
A coleção Users armazena informações sobre os usuários registrados no sistema. Cada usuário é identificado por seu e-mail, nome, função (como administrador, pesquisador ou usuário externo), e uma senha criptografada (password_hash). Os usuários podem ser associados a diferentes papéis, cujas permissões são definidas por associações na coleção Roles e Permissions. Para controle de autenticação, a coleção Tokens armazena tokens de acesso vinculados aos usuários. Esses tokens incluem informações como endereço IP, agente do usuário e data de expiração, permitindo autenticação segura e controle de sessões.
Esse modelo de dados suporta todo o ciclo de vida do sistema, desde o registro de domínios e problemas até a execução de experimentos e a análise de resultados, além de oferecer mecanismos de controle de acesso e compartilhamento de informações.
Processo de Automação para a Análise Empírica de Planejadores
Uma das principais dificuldades na avaliação de um conjunto de planejadores em um lote de problemas, considerando um conjunto de métricas de interesse, está na seleção do(s) planejador(es), seleção do(s) domínio(s) e problema(s), associação de métricas diferentes por planejador, visualização e gerenciamento do histórico de resultados. Associados a isso, na execução dos experimentos, existe a preocupação com o controle máximo do tempo permitido por problema, limite de memória e o uso de ambientes virtuais (Docker) para criar ambientes reprodutíveis e isolados.
A plataforma Planalyzing foi projetada para automatizar a avaliação de planejadores, permitindo que os usuários realizem o agendamento, a execução e a análise de experimentos de forma reprodutível em um conjunto de domínios e problemas conforme processo descrito na Figura 7. Essa abordagem otimiza o processo de avaliação, eliminando tarefas repetitivas e reduzindo os esforços manuais.
Registro de Domínios, Problemas e Planejadores pelo Administrador
O processo de automação da plataforma Planalyzing começa com o administrador registrando os dados básicos no sistema, incluindo domínios, problemas e planejadores. O administrador acessa a interface web e insere as informações detalhadas de cada domínio, como nome, descrição e definição em PDDL (Planning Domain Definition Language). Em seguida, são registrados os problemas relacionados a cada domínio, associando as definições do problema também no formato PDDL. Para completar os requisitos mínimos necessário para um experimento, o administrador também adiciona os planejadores ao sistema, incluindo seus nomes, descrições e configurações de execução, como comandos de linha e padrões de saída.
Cada planejador pode ter múltiplas versões, e para cada versão são configuradas métricas específicas que serão extraídas dos resultados experimentais. Para cada versão, existe um conjunto de métricas padrões sugeridas pela plataforma, que é registrada no formato chave/valor, onde o valor é uma expressão regular que será aplicado sobre o arquivo de saída para cada problemas resolvido pelo planejador, são elas: o tempo de execução, o tempo de busca e tamanho da solução. Após o registro, a plataforma valida automaticamente os dados inseridos, verificando consistência, integridade e possíveis erros de configuração. Caso os dados sejam considerados inválidos, o administrador é notificado para ajustá-los. Quando os dados são aprovados, eles são armazenados no banco de dados, ficando disponíveis para uso pelos pesquisadores durante o agendamento dos experimentos.
Agendamento de Experimentos pelo Pesquisador
Com os dados registrados pelo administrador, os pesquisadores podem acessar a plataforma para configurar experimentos. O agendamento começa com o pesquisador selecionando domínios e problemas de interesse, podendo escolher problemas específicos ou incluir todos os problemas associados a um domínio. Em seguida, o pesquisador seleciona os planejadores e as versões que deseja testar.
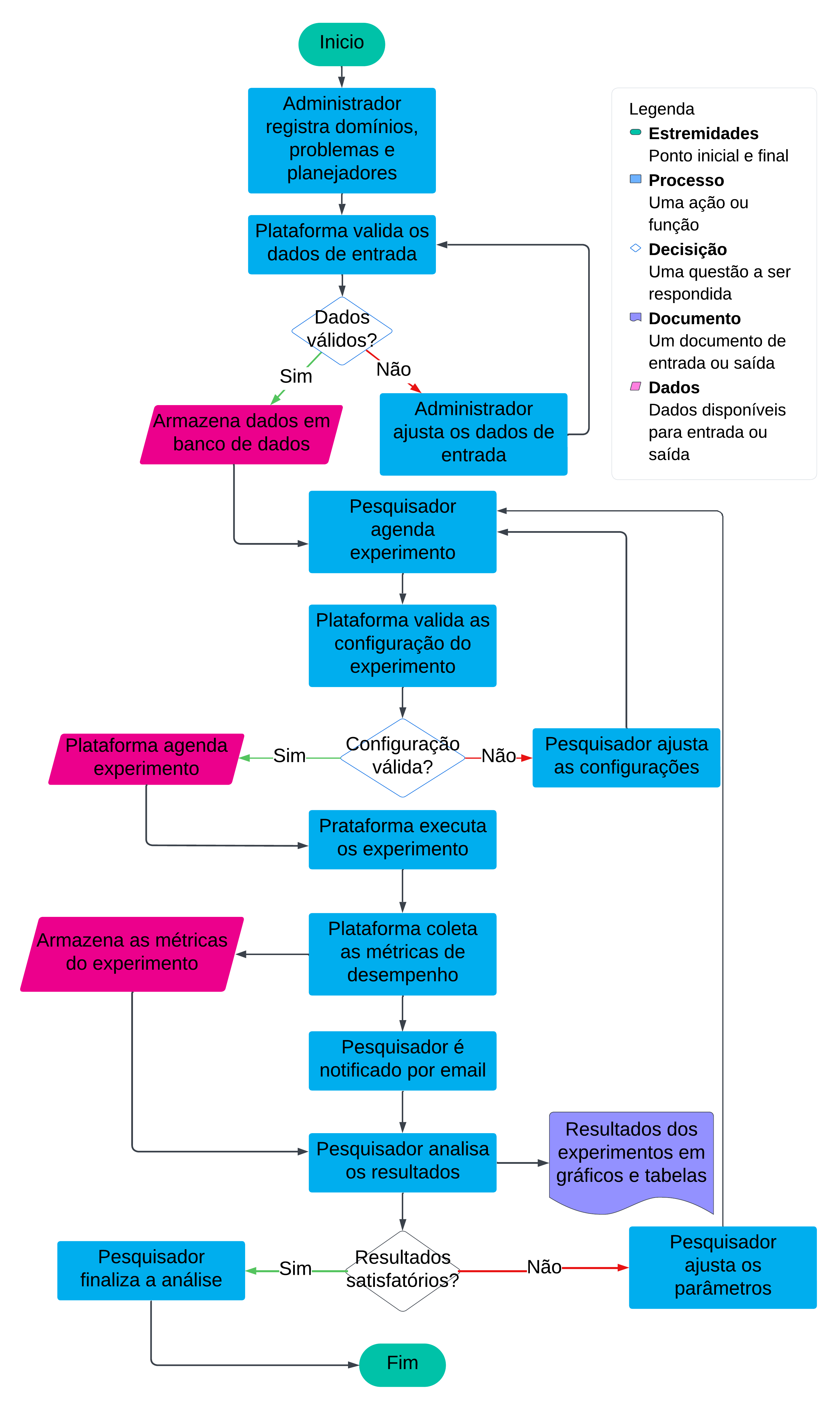
Após configurar o experimento, a plataforma valida as informações fornecidas para garantir que a configuração está consistente com os dados do sistema. Se a configuração for considerada inválida, o pesquisador é notificado e pode ajustar os parâmetros antes de reenviar. Quando tudo está correto, o experimento é agendado no sistema, com os dados sendo registrados no banco de dados. A configuração é então passada para o módulo de orquestração, que coordena a execução do experimento por meio de workflows em um gerenciador de tarefas.
Execução dos Experimentos pela Plataforma Planalyzing
Após o experimento ser agendado, a plataforma Planalyzing inicia o processo de execução utilizando o sistema de orquestração. O agendador de tarefas ativa o DAG (Directed Acyclic Graph) responsável por executar os experimentos, iniciando com a recuperação dos dados de configuração do banco de dados. O módulo CommandGenerator gera os comandos necessários para cada combinação de planejador e problema, baseando-se nos parâmetros fornecidos. Esses comandos são passados para o ExperimentManager, que instancia contêineres Docker isolados para executar os planejadores. Cada contêiner processa todos os problemas de um planejador, garantindo que os experimentos sejam executados em paralelo para otimizar o tempo de execução. Os resultados gerados pelos planejadores são gravados no sistema de arquivos em um formato padronizado, seguindo o padrão de nomeação especificado durante a configuração.
Após a execução, o ResultProcessor é acionado para ler os arquivos de saída, aplicar expressões regulares e extrair as métricas definidas. Essas métricas são então armazenadas no banco de dados, vinculadas ao experimento correspondente.
Notificação e Análise Empírica dos Resultados
Quando as métricas do experimento são armazenadas, o pesquisador é automaticamente notificado por e-mail por meio do módulo NotificationManager. O e-mail informa que o experimento foi concluído e fornece um link direto para a interface de análise. Na plataforma, o pesquisador pode acessar gráficos e tabelas interativas que comparam os resultados obtidos entre diferentes planejadores, problemas e domínios. Esses gráficos destacam métricas como desempenho, tempo de execução e tamanho das soluções.
Caso os resultados não sejam satisfatórios, o pesquisador pode ajustar os parâmetros do experimento diretamente na plataforma, refinando domínios, problemas, planejadores ou métricas, e reexecutar o processo. Se os resultados atenderem às expectativas, o pesquisador pode finalizar a análise e exportar os dados e gráficos para relatórios. Esse ciclo de experimentação e análise empírica permite aos pesquisadores explorar a eficácia de diferentes planejadores em diversos cenários, promovendo uma avaliação detalhada e sistemática dos algoritmos testados.